Hur Google skapar kunskapspaneler
Kunskapsdiagrammets inflytande växer snabbt och bör inkluderas i din SEO-strategi.

Förekomsten av kunskapspaneler har ökat i Googles SERP i flera år. Som ett resultat får de klassiska sökresultaten, även kända som ”10 blå länkar”, mer konkurrens när det gäller att fånga den som sökers uppmärksamhet.
Eller borde vi hellre kalla det ”frågarna”? Eftersom de flesta sökfrågor är implicit formulerade frågor som kräver ett svar.
Google vill använda SERP-funktionerna för att svara direkt på frågorna. Dessa funktioner är ett fönster in i kunskapsdiagrammet eller är direkt eller indirekt associerade med det.
Den här artikeln kommer att förklara hur Google skapar kunskapspaneler – och hur de fungerar.
Vad är kunskapspaneler?
Entiteter spelar en direkt eller indirekt roll i många sökfrågor. Det är därför du hittar olika boxvarianter i SERP:erna för många sökfrågor.
Så snart Google känner igen det med en sökfråga som ett ämne direkt efter att enheten frågade om kunskapspanelen levereras. Kunskapspanelen kan även kallas entitetsbox och den levereras för nästan alla entitetstyper.
En kunskapspanel levereras dock inte för varje enhet av en typ. Entiteten måste fångas i kunskapsdiagrammet.
En av de grundläggande frågorna för SEOs är vilka enheter som ska inkluderas i Google Knowledge Graph. Enligt Google registreras endast namngivna entiteter från klasserna av följande entitetstyper i Kunskapsdiagrammet.
- Böcker och bokserier
- Utbildningsinstitutioner, myndigheter, lokala butiker, företag
- Händelser
- Filmer och filmserier
- Musikgrupper och album
- Personer
- Platser
- Idrottslag
- TV-serie
- TV-spel och serier
- Webbplatser eller domäner
Men inte alla enheter från dessa klasser är associerade med en kunskapspanel som presenteras i SERP:erna. Enheterna ska ha en viss social relevans eller auktoritet inom respektive område.
Den klassiska kunskapspanelen kan kännas igen av dela-knappen i panelens övre del.
Kunskapspaneler ska inte förväxlas med affärsboxar. Dessa är inte baserade på Knowledge Graph, utan på en post på Google Business. I vilken utsträckning data från Google Business också beaktas i kunskapsdiagrammet är inte klart, men det är inte osannolikt.
Google använder olika mallar för kunskapspanelen. Platshållarna för innehållet i kunskapspanelen varierar beroende på vilken enhet eller enhetstyp som söks efter. Platshållarna baseras på standardattributen för respektive enhetstyp.
Hur avgör Google relevansen av en enhet för att betjäna en kunskapspanel?
Kriterierna som Google utvärderar denna relevans är inte tydligt dokumenterade eller så finns det inga konkreta uttalanden från Google.
Wikipedia spelar en speciell roll för bevisenheten. Det säkraste sättet att bli erkänd som en enhet är att ha en post på Wikipedia.
Men andra plattformar som tillhandahåller semistrukturerad data, som Soundcloud, kan också användas av Google för att identifiera enheter, vilket hacket för sökordet ”SEO services India” har visat.
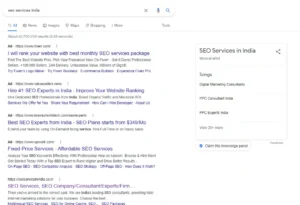
Där blir det tydligt att SoundCloud användes som källa för enhetsdetekteringen. Webbplatser som SoundCloud eller Wikipedia presenterar alltid information i en konsekvent struktur. Detta gör att informationen enkelt kan extraheras från webbplatserna utan uppmärkningar.
Hur skapar Google en kunskapspanel?
Kunskapspanelerna presenterades först i SERP:erna i och med introduktionen av Knowledge Graph 2012.
I Googles patent Att tillhandahålla kunskapspaneler med sökresultat hittar man kunskapspanelens grundläggande metodik och syfte. Syftet för användare av en sökmotor beskrivs enligt följande.
”Kunskapspaneler kan förbättra användarnas sökupplevelser, särskilt för frågor riktade till inlärning, surfning eller upptäckt. Till exempel förser kunskapspanelen användarna med grundläggande faktainformation eller en sammanfattning av information om en viss enhet som hänvisas till i en sökfråga. Kunskapspaneler kan hjälpa användare att navigera till relaterat innehåll på ett sömlöst och naturligt sätt som paneler med nytt innehåll kanske inte kan tillhandahållas på annat sätt. av en användare utan att välja flera sökresultat kan också hjälpa användare att få information snabbare än om användarna skulle behöva klicka sig igenom flera sökresultat för att få informationen.”
Här är ett utdrag ur patentet om metodiken för att leverera kunskapspanelen:
”Metoder, system och apparater, inklusive datorprogram kodade på ett datorlagringsmedium, för att tillhandahålla kunskapspaneler med sökresultat. I en aspekt inkluderar en metod att erhålla sökresultat som är lyhörda för en mottagen förfrågan. En faktisk enhet som hänvisas till av frågan identifieras. Innehåll identifieras för visning i en kunskapspanel för den faktiska enheten. Innehållet innehåller minst ett andra innehåll och erhålls från minst en andra resurs. en annan resurs än den första resursen Data tillhandahålls som gör att de identifierade sökresultaten och kunskapspanelen presenteras på en sökresultatsida.”
Den grundläggande funktionaliteten vid leverans av en kunskapspanel kan sammanfattas i följande processsteg:
- Identifiering av en eller flera relevanta enheter i sökfrågan
- Identifiering av relevanta källor för huvuddelen
- Skapande av relevanta sökresultat för sökfrågan
- Kontrollera om sökfrågan verkligen hänvisar till den faktiska huvuddelen
entitet - Fastställande av en enhetstyp för den efterfrågade huvudenheten
- Val av en lämplig kunskapspanelmall som matchar den fastställda Entity Type
- Identifiering av relevanta innehållselement relaterade till huvudenheten från en relevant och pålitlig källa.
- Fastställande av ett annat innehållselement från en annan källa.
- Fyllning av platshållarna i den valda kunskapspanelmallen med de valda innehållselementen.
- Slå samman sökresultat och kunskapspanel på en sökresultatsida
Jag tycker att det är spännande att inse att varje entitetstyp tilldelas sin egen kunskapspanelmall med motsvarande platshållare.
Entitetstypen för respektive entitet som representeras av en kunskapspanel anges alltid under entitetens namn. Beroende på vilka standardattribut som är tilldelade entitetstypen och för vilka attribut värdena är tillgängliga, specificeras innehåll i kunskapspanelen.
Hur genererar Google bilder för kunskapspanelen?
Angående frågan om vilka bilder som väljs ut för kunskapspanelen så tittade jag på några Google-patent från de senaste åren.
Urval av representativa bilder
Detta patent beskriver hur Google kunde välja representativa bilder för enheter av typen ”person” för motsvarande kunskapspanel.
Stegen är som följer:
- Få tillgång till ett urval av möjliga bilder
- Klustra efter likhet
- Identifiera de mest populära klustren
- Bestäm om bilden är ett porträtt eller inte
- Tilldela porträttpoäng
- Välj den mest representativa bilden
- Visa bilden i kunskapspanelen
Valet av möjliga bilder samt grupperingen av dessa i kategorier bestäms beroende på närheten till enheten samt bildförhållandet. Det kommer att vara mycket troligt att maskininlärningsmetoder används.
System och metod för att associera bilder med semantiska enheter
Ett annat spännande Google-patent relaterat till bilder och enheter beskriver hur Google Images kunde sammanställa bilderna för semantiskt förval.
”Ett system och datorimplementerad metod för att associera bilder med semantiska enheter och tillhandahålla sökresultat med de semantiska enheterna. En bilddatabas innehåller en eller flera källbilder som är associerade med en eller flera bildetiketter. En dator kan generera ett eller flera dokument som innehåller etiketterna som är associerade med varje bild. Analys kan utföras på ett eller flera dokument för att associera källbilderna med semantiska sökningar med semantiska resultat. som svar på mottagning av en målbild som en sökfråga, kan målbilden jämföras med källbilderna för att identifiera liknande bilder.”
I detta patent är bilder märkta med attribut. genom vilken bilderna kan tilldelas specifika enheter. Dessa attribut identifieras initialt via bildigenkänning av en initial bild. Ytterligare attribut läggs till via attribut för liknande bilder och liknande enheter, förmodligen av samma typ. Så framträder bildens betydelse.
Dessa patent beskriver några tillvägagångssätt för hur Google kan specificera bilder för kunskapspaneler. Enligt min mening är också bildens källa avgörande, vilken bild Google väljer ut den mest relevanta bilden för en entitet och därmed använder i kunskapspanelen.
Populära källor för människors bilder verkar vara Wikidata, Wikipedia, Wikimedia, sociala medieprofiler (t.ex. LinkedIn, Twitter) och välkända tidskrifter. I vilken utsträckning rankningen i bildsökningen korrelerar med valet av bilden/bilderna för kunskapspanelen är oklart.
Kunskapsdiagrammets inflytande växer snabbt
SERP-funktionernas inflytande ökar för varje år och med det inflytandet från Kunskapsdiagrammet på sökresultaten. De klassiska blå länkarna tappar mer uppmärksamhet och därmed relevans.
Entiteter är i centrum för kunskapsdiagrammet och kommer att få en ökande inverkan på SERP:erna.
När det gäller röstsökning spelar SERP-funktioner som utvalda utdrag och kunskapspaneler också en viktig roll.
Ändringarna i SERPs på grund av MUM-uppdateringen kan redan ses, liksom den allt mer centrala rollen för entitetsbaserade sökningar.
Därför bör SEO:are inte längre uppfatta detta ämne som ett ”trevligt att ha”. Kunskapsdiagrammet bör inkluderas i dina SEO-strategier.
Behöver du hjälp med SEO?
Kontakta oss!
